Project Description
This project classifies Tokopedia product reviews into Positive, Neutral, or Negative sentiment using a Support Vector Machine (SVM) algorithm, achieving an impressive 95% accuracy. Built with Python and Jupyter Notebooks, the project implements an Explainable AI (XAI) approach to provide transparency in the model's predictions.
The system was trained on 500 reviews across 5 different product categories (Fashion, Electronics, Food, etc.), proving its robustness and versatility in real-world e-commerce scenarios.
Notes & Reflection
One of the most fascinating parts of this project was applying Explainable AI. Instead of treating the SVM as a "black box", I analyzed the coefficients of the Linear Kernel to see exactly which keywords influenced the sentiment classification the most. It was incredibly rewarding to visualize how the model "thinks".
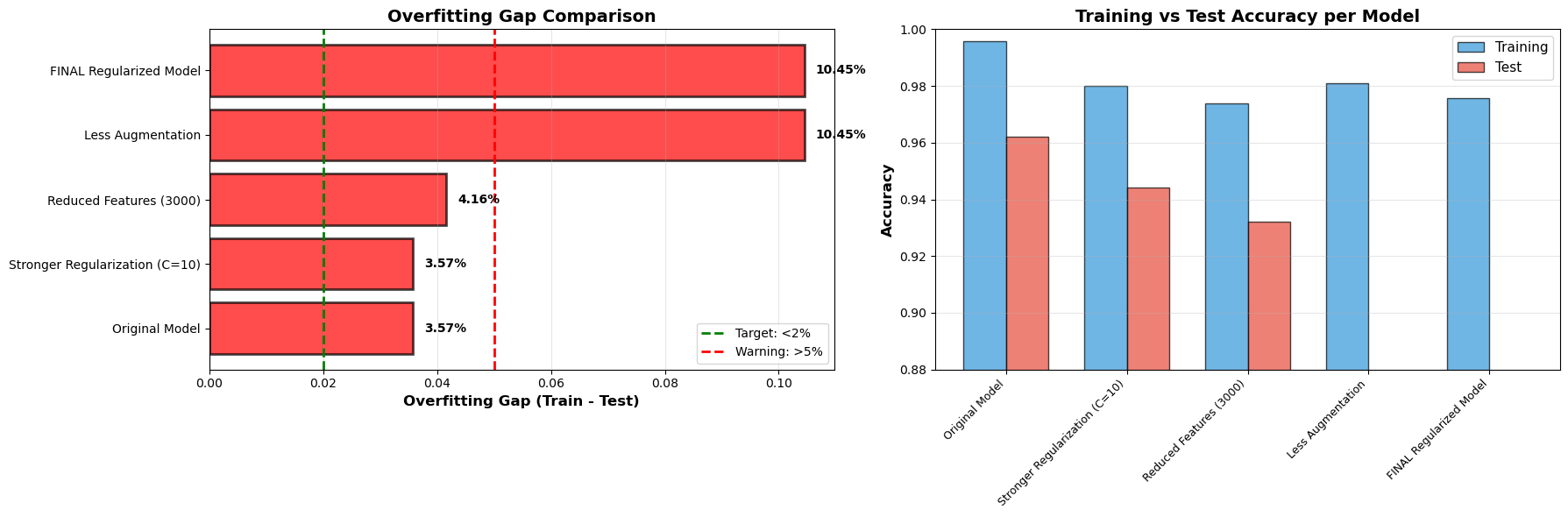
I also faced challenges with imbalanced data, which I tackled using Data Augmentation (Synonym Replacement and Random Insertion/Deletion) and resampling techniques. Adding behavioral feature engineering—like analyzing the intensity of punctuation (! or ?)—helped the model capture human emotion far better than standard text alone. This project significantly deepened my understanding of natural language processing and model interpretability.
Model Performance & Data Progression
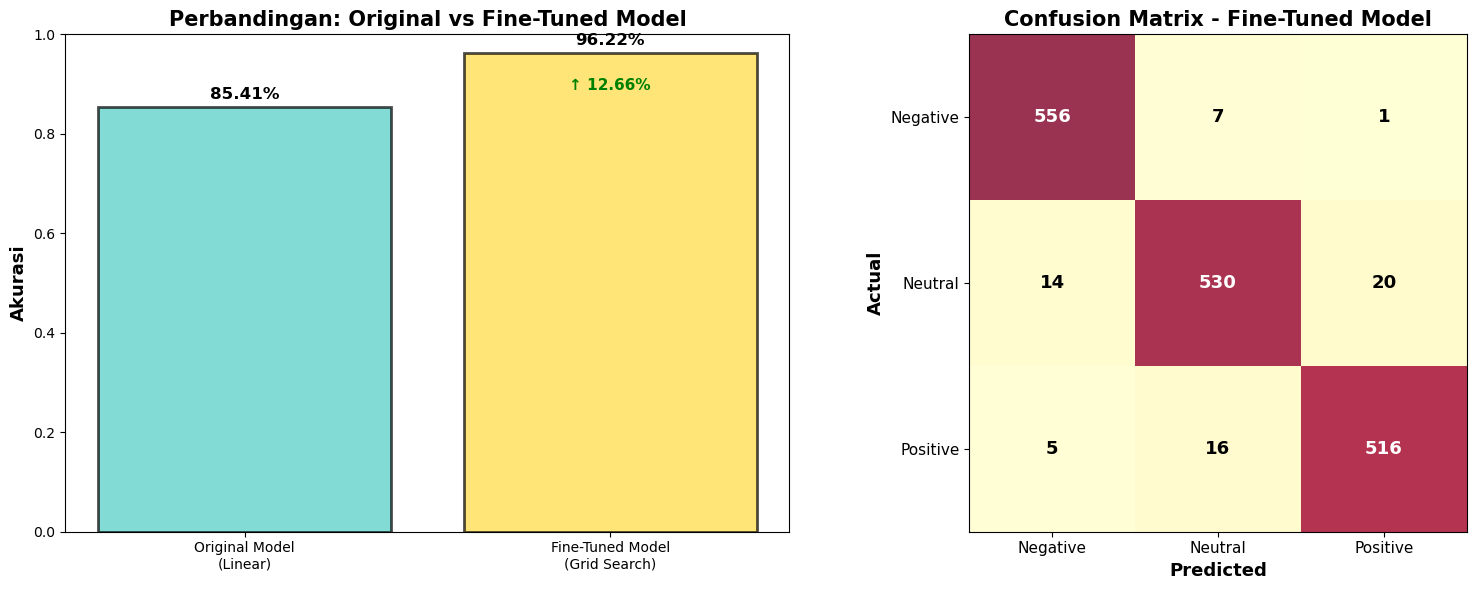
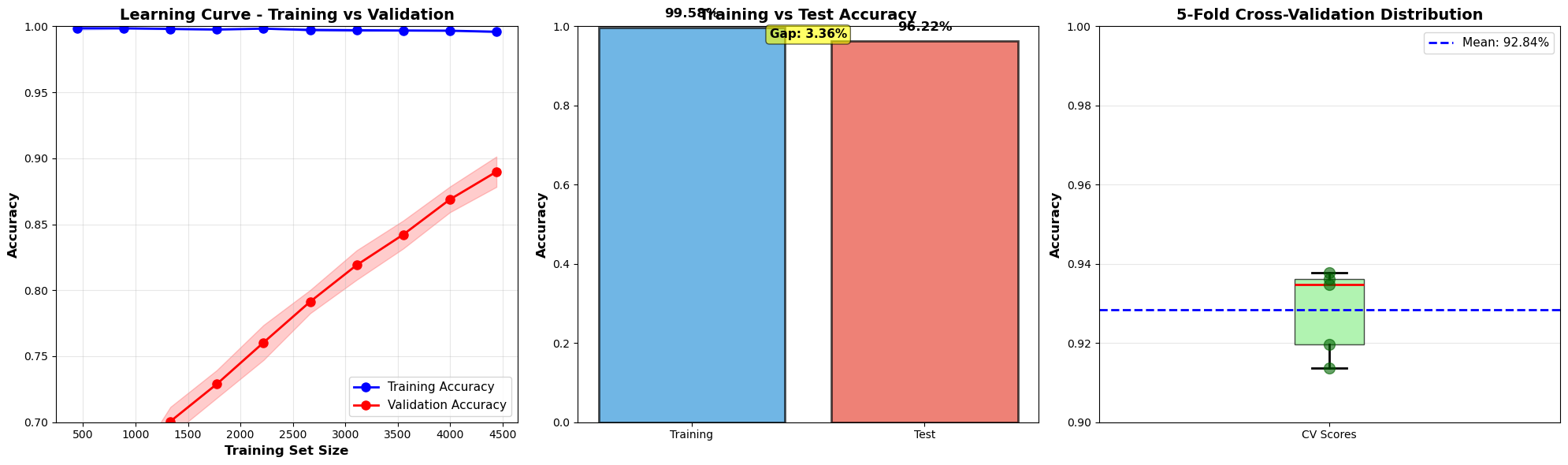
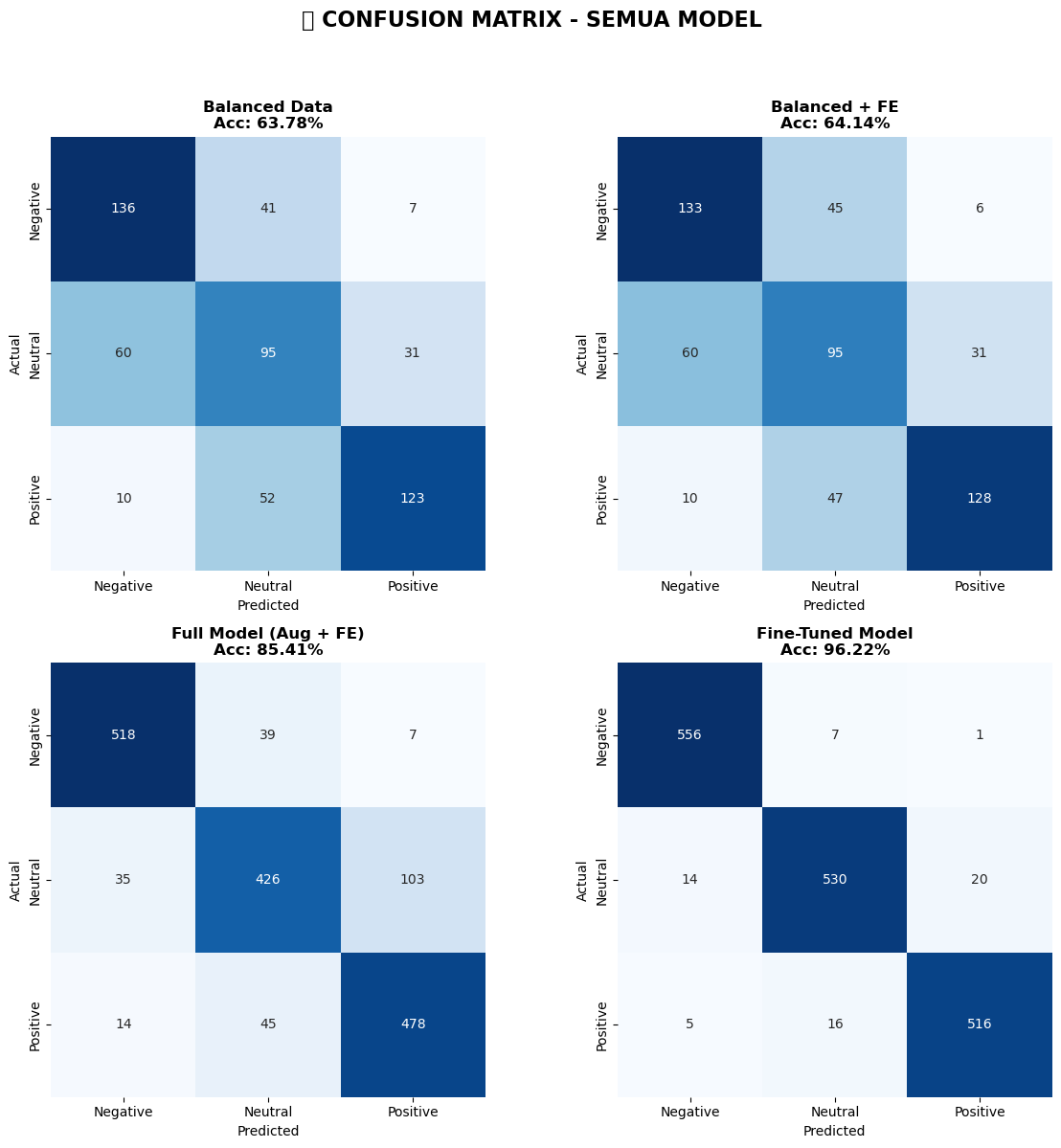
To ensure the most accurate sentiment classification, the model underwent multiple iterations of enhancement, ultimately achieving a peak accuracy of 96.22%.
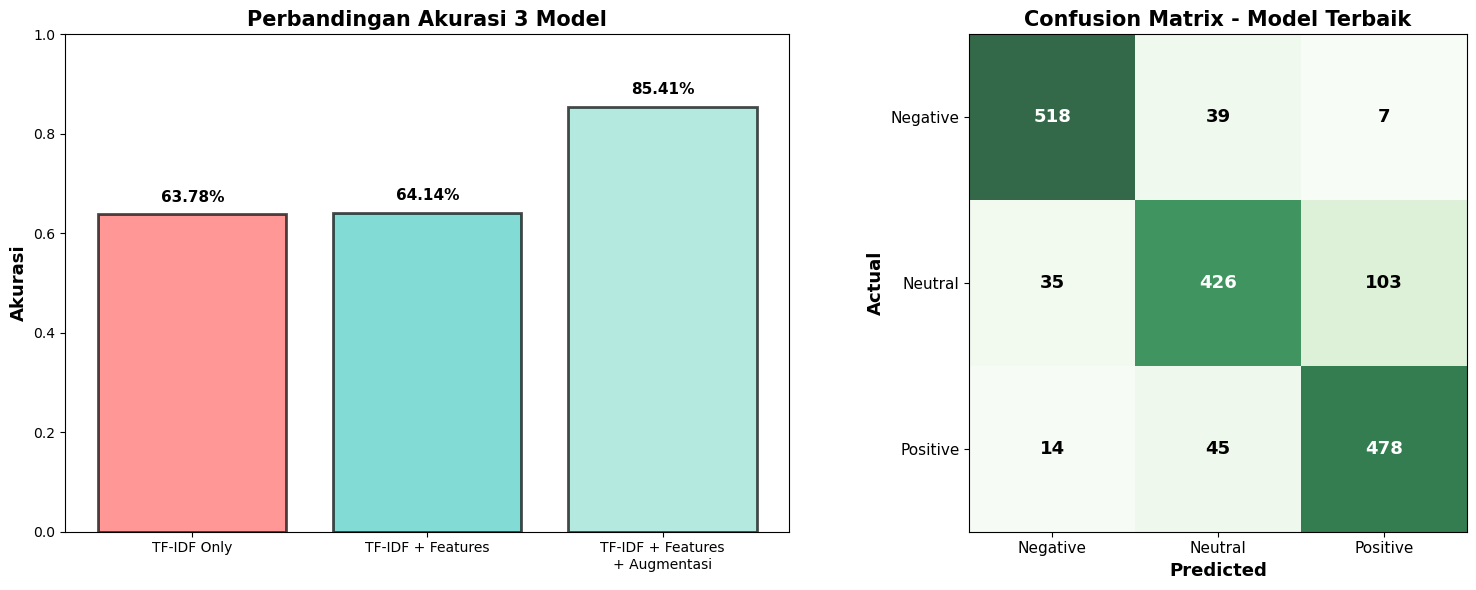
- Baseline (TF-IDF Only): 63.78%
- TF-IDF + Custom Features: 64.14%
- TF-IDF + Features + Data Augmentation: 85.71%
- Fine-Tuned Model (Grid Search): 96.22%
This massive +49.44% improvement from the baseline proves the effectiveness of robust data augmentation and precise hyperparameter tuning.

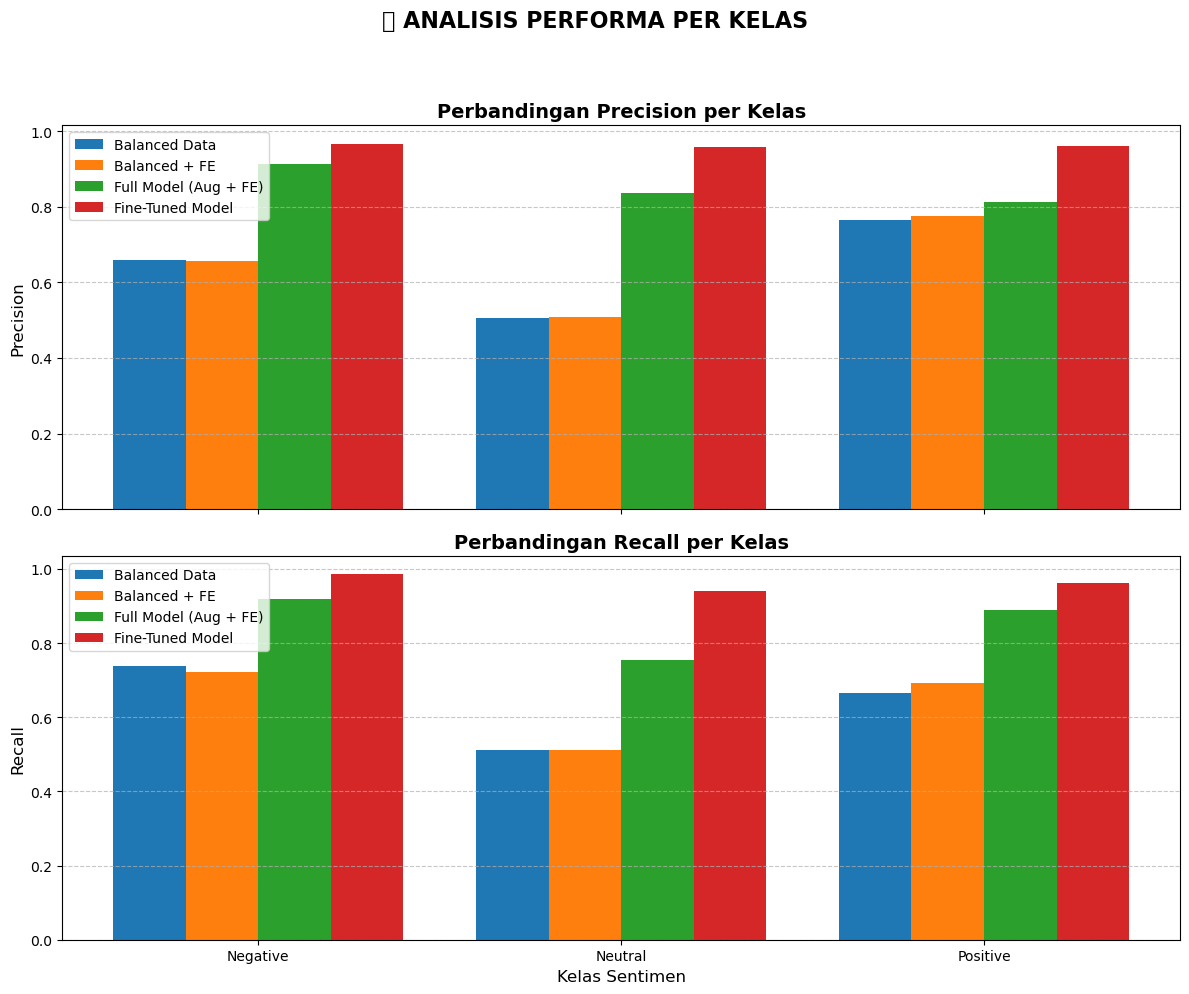
Data Visualizations & Metrics
Below are the exported analysis graphs from the Jupyter Notebook detailing the data distributions, confusion matrices, and the progressive performance improvements.